April 2, 2020
Using automated data augmentation to advance our Waymo Driver
To help safely navigate the complexities of the road, our self-driving technology needs to see and identify what’s around it. To perceive its surroundings, the Waymo Driver relies on our powerful custom sensor suite of lidar, cameras, and radars, while neural nets empower the “brain” of our self-driving system to understand the sensor data and respond to a wide range of scenarios.
The situations we experience on the road and in simulation give us opportunities to train machine learning models and continuously improve our self-driving technology. In order to create robust neural nets, we need a large and diverse set of training data. The process of collecting a meaningful dataset—from driving around to labeling examples—is time-intensive and expensive. To make the task even tougher, certain situations are simply less likely to occur. For example, in order to capture a seal crossing the street or a man breakdancing on the sidewalk, you have to be in the right place at the right time. To make the most of these rare moments and further improve our self-driving system’s perception, we teamed up with our Google Research colleagues from the Brain Team to extend automated data augmentation research and test it against Waymo’s dataset.
Increasing a dataset without new data
Data augmentation allows us to increase the quantity and diversity of data we observe without additional collecting or labeling costs. The principle behind augmenting data is simple. Let’s say you have a picture of a dog. By using various image augmentation operations such as rotation, cropping, image mirroring, color shifting, etc., you can morph and transform the photo—but it doesn’t change the fact that it’s an image of a dog. These simple transformations turn one image of a dog into many, though determining which combinations of augmentation operations to use and applying them requires a lot of manual engineering.

Data augmentation on dog images
With AutoAugment [1], Google Brain designed a new search space consisting of augmentation policies — combinations of augmentation operations. They were able to automatically explore which augmentation policies to use through reinforcement learning. By finding the optimal image transformation policies from the data itself, Brain Team was able to improve image recognition tasks on various academic datasets and extend these ideas to object localization problems on COCO dataset [2]. They also discovered a way to substantially reduce the computational cost of searching for effective data augmentation policies [3], making it an effective and inexpensive tool for us to use across our dataset collected over 20 million self-driven miles on public roads.
Applying methods proven at Google to Waymo’s self-driving tasks
In collaboration with our Google Research colleagues from the Brain team, we’re extending this research to automatically discover optimal data augmentation policies to improve perception tasks for our Waymo Driver.
In 2019, we started applying automated data augmentation techniques from RandAugment [3] to Waymo image-based classification and detection tasks. We achieved significant improvements in several classifiers and detectors, including those that help classify foreign objects such as construction equipment and animals. After the success we experienced with image-based data, we explored whether automated data augmentation strategies could improve lidar 3D detection tasks as well.
Lidar is one of Waymo’s core sensors. It not only paints a picture of its surroundings in 3D up to 300 meters away, but it also provides our self-driving technology important context for where objects are and where they may be going. Because of our custom-designed lidar’s ability to provide detailed 3D information, lidar-based models are key to our system, and ensure we accurately detect and track all objects on the road. While data augmentation is commonly adopted to improve the quality and robustness of lidar point cloud detection models, current augmentation strategies are limited because of their manual design. Since no suitable off-the-shelf solution for point cloud augmentation existed, we decided to build one.
While augmenting images is no easy task, augmenting a lidar point cloud is literally a whole dimension more complex. As a result, the search space of automated augmentation techniques used for image classification and object detection cannot directly be reused for point clouds. Due to the nature of geometric information in 3D data, transformations for point clouds typically have a large number of parameters including geometric distance, operation strength, sampling probability, etc., and certain image augmentation techniques, such as color shifting, simply wouldn’t apply to monochromatic 3D data. Therefore, we created a new point cloud augmentation search space to discover policies specifically designed for point cloud datasets.
Building a new augmentation strategy for lidar point clouds
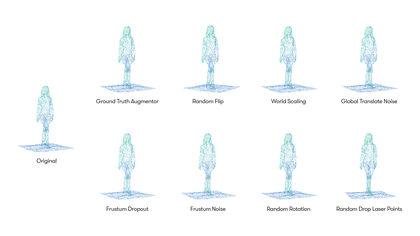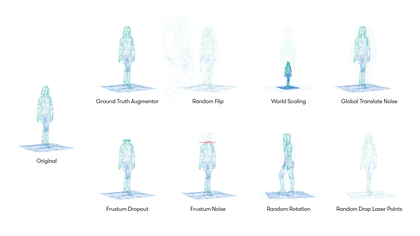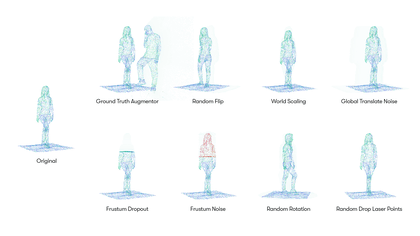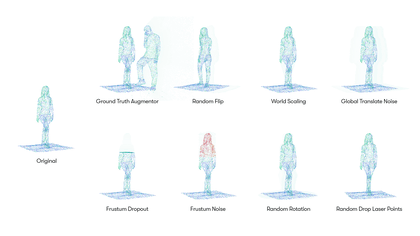
The search space we created for our lidar point clouds includes eight augmentation operations, including:
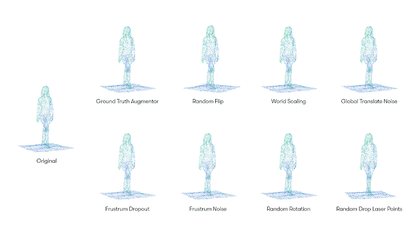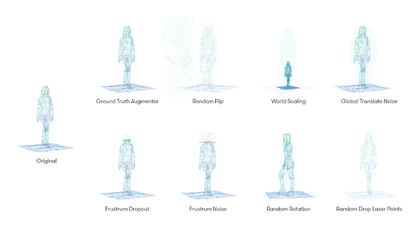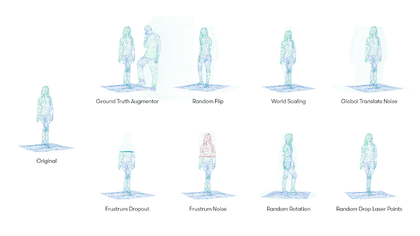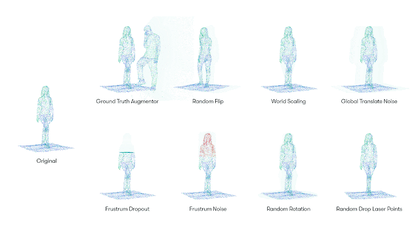
Each augmentation operation is associated with a probability and specific parameters. For example, the GroundTruthAugmentor has parameters denoting the probability for sampling vehicles, pedestrians, cyclists, whereas the GlobalTranslateNoise operation has parameters for the distortion magnitude of translation operation on x, y and z coordinates.
To automate the process of finding good augmentation policies for lidar point clouds, we created a new automated data augmentation algorithm - Progressive Population Based Augmentation (PPBA)[8]. PPBA builds on our previous Population Based Training (PBT)[7] work, where we train neural nets with evolutionary computation, which uses principles similar to Darwin’s Natural Selection Theory. PPBA learns to optimize augmentation strategies effectively and efficiently by narrowing down the search space at each population iteration and adopting the best parameters discovered in past iterations.

Waymo’s Progressive Population Based Augmentation focuses on optimizing a subset of augmentation parameters of the whole search space in each training iteration. The best parameters in the past iterations are recorded as references for mutating parameters in future iterations.
By automating data augmentation to lidar point clouds in Waymo’s Open Dataset, one of the largest and most diverse multi-sensor self-driving datasets ever released, PPBA achieves significant performance improvement across detection architectures. Our experiments also show PPBA is much faster and more effective in finding data augmentation strategies compared to a random search or a PBA [5] baseline. Additionally, because we rely on labeled lidar data to train our neural nets, PPBA also allows us to save on labeling costs, in turn improving our data efficiency as one labeled example becomes many. As the figures below show, our 3D detection control experiments on the Waymo Open Dataset show that using PPBA is up to 10 times more data efficient than training nets without augmentation.
What’s Next
Our experiments show that by applying automated data augmentation to lidar data, we can significantly improve 3D object detection without additional data collection or labeling. On the baseline 3D detection model, our method is up to 10x more data efficient than without augmentation, enabling us to train machine learning models with fewer labeled examples, or use the same amount of data for better results, at a lower cost. The increase in data efficiency is especially important as it means we can speed up the training process and improve the perception tasks of our fifth-generation Waymo Driver, enabling us to serve our Waymo Via partners and Waymo One riders more effectively and efficiently.
We look forward to continuing our work with Google Research, Brain Team, so stay tuned for more!
Join our team and help us build the World’s Most Experienced Driver. Waymo is looking for talented software and hardware engineers, researchers, and out-of-the-box thinkers to help us tackle real-world problems, and make the roads safer for everyone. Come work with other passionate engineers and world-class researchers on novel and difficult problems—learn more at waymo.com/joinus.
*Acknowledgements
This collaboration between Waymo and Google was initiated and sponsored by Drago Anguelov of Waymo, Quoc Le and Jon Shlens at Google. The work was conducted by Shuyang Cheng, Chunyan Bai, Yang Song and Peisheng Li of Waymo, and Zhaoqi Leng, Ekin Dogus Cubuk, Jiquan Ngiam and Barret Zoph of Google. Extra thanks for the support of Congcong Li, Chen Wu, Ming Ji, Weiyue Wang, Zhinan Xu, Xin Zhou, James Guo, Shirley Chung, Yukai Liu, Pei Sun of Waymo, Matthieu Devin, Zhifeng Chen, Ben Caine and Vijay Vasudevan of Google and Ang Li of DeepMind.
Reference[1] Cubuk, E.D., Zoph, B., Mane, D., Vasudevan, V., Le, Q.V.: Autoaugment: Learning augmentation policies from data. arXiv preprint arXiv:1805.09501 (2018)[2] Zoph, B., Cubuk, E.D., Ghiasi, G., Lin, T.Y., Shlens, J., Le, Q.V.: Learning data augmentation strategies for object detection. arXiv preprint arXiv:1906.11172 (2019)[3] Cubuk, E.D., Zoph, B., Shlens, J., Le, Q.V.: Randaugment: Practical data augmentation with no separate search. arXiv preprint arXiv:1909.13719 (2019)[4] Sun, P., Kretzschmar, H., Dotiwalla, X., Chouard, A., Patnaik, V., Tsui, P., Guo, J., Zhou, Y., Chai, Y., Caine, B., Vasudevan, V., Han, W., Ngiam, J., Zhao, H., Timofeev, A., Ettinger, S., Krivokon, M., Gao, A., Joshi, A., Zhang, Y., Shlens, J., Chen, Z., Anguelov, D.: Scalability in perception for autonomous driving: Waymo open dataset. arXiv preprint arXiv:1912.04838 (2019)[5] Ho, D., Liang, E., Stoica, I., Abbeel, P., Chen, X.: Population based augmentation: Efficient learning of augmentation policy schedules. arXiv preprint arXiv:1905.05393 (2019)[6] Lang, A.H., Vora, S., Caesar, H., Zhou, L., Yang, J., Beijbom, O.: Pointpillars: Fast encoders for object detection from point clouds. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. pp. 12697–12705 (2019)[7] Jaderberg, M., Dalibard, V., Osindero, S., Czarnecki, W.M., Donahue, J., Razavi, A., Vinyals, O., Green, T., Dunning, I., Simonyan, K., Fernando, C., Kavukcuoglu, K.: Population based training of neural networks. arXiv preprint arXiv:1711.09846 (2017)[8] Cheng, S., Leng, Z., Cubuk, E.D., Zoph, B., Bai, C., Ngiam, J., Song, Y., Caine, B., Vasudevan, V., Li, C., Le, Q.V., Shlens, J., Anguelov, D.: Improving 3D Object Detection through Progressive Population Based Augmentation. arXiv preprint arXiv:2004.00831 (2020)