December 10, 2018
Learning to Drive: Beyond Pure Imitation

At Waymo, we are focused on building the world’s most experienced driver. And just like any good driver, our vehicle needs to perceive and understand the world around it by recognizing surrounding objects and predicting what they might do next, before deciding how to drive safely while obeying the traffic rules.
In recent years, the supervised training of deep neural networks using large amounts of labeled data has rapidly improved the state-of-the-art in many fields, particularly in the area of object perception and prediction, and these technologies are used extensively at Waymo. Following the success of neural networks for perception, we naturally asked ourselves the question: given that we had millions of miles of driving data (i.e., expert driving demonstrations), can we train a skilled driver using a purely supervised deep learning approach?
This post — based on research we’ve just published* — describes one exploration to push the boundaries of how we can employ expert data to create a neural network that is not only able to drive the car in challenging situations in simulation, but also reliable enough to drive a real vehicle at our private testing facility. As described below, simple imitation of a large number of expert demonstrations is not enough to create a capable and reliable self-driving technology. Instead, we’ve found it valuable to bootstrap from good perception and control to simplify the learning task, to inform the model with additional losses, and to simulate the bad rather than just imitate the good.
Creating ChauffeurNet: A Recurrent Neural Network for Driving
In order to drive by imitating an expert, we created a deep recurrent neural network (RNN) named ChauffeurNet that is trained to emit a driving trajectory by observing a mid-level representation of the scene as an input. A mid-level representation does not directly use raw sensor data, thereby factoring out the perception task, and allows us to combine real and simulated data for easier transfer learning. As shown in the figure below, this input representation consists of a top-down (birds-eye) view of the environment containing information such as the map, surrounding objects, the state of traffic lights, the past motion of the car, and so on. The network is also given a Google-Maps-style route that guides it toward its destination.
ChauffeurNet outputs one point along the future driving trajectory during each iteration, while writing the predicted point to a memory that is used during its next iteration. In this sense, the RNN is not traditional, because the memory model is explicitly crafted. The trajectory output by ChauffeurNet, which consists of ten future points, is then given to a low-level controller that converts it to control commands such as steering and acceleration that allow it to drive the car.
In addition, we have employed a separate “PerceptionRNN” head that iteratively predicts the future of other moving objects in the environment and this network shares features with the RNN that predicts our own driving. One future possibility is a deeper interleaving of the process of predicting the reactions of other agents while choosing our own driving trajectory.
Rendered inputs and output for the driving model. Top-row left-to-right: Roadmap, Traffic lights, Speed-limit, and Route.
Bottom-row left-to-right: Current Agent Box, Dynamic Boxes, Past Agent Poses, and the output Future Agent Poses.
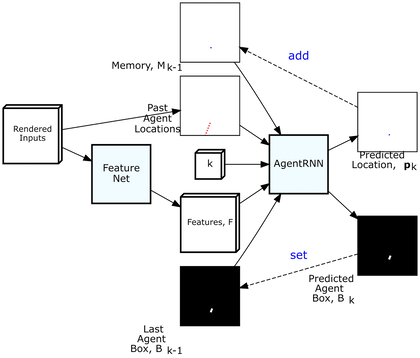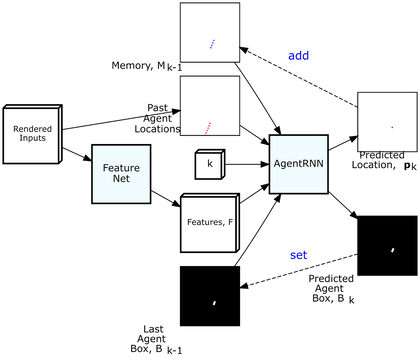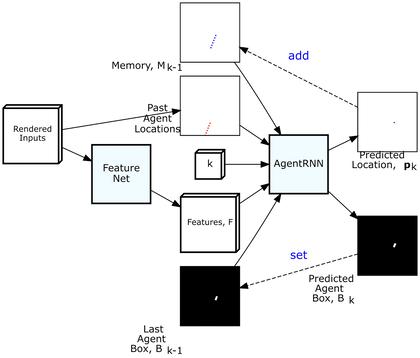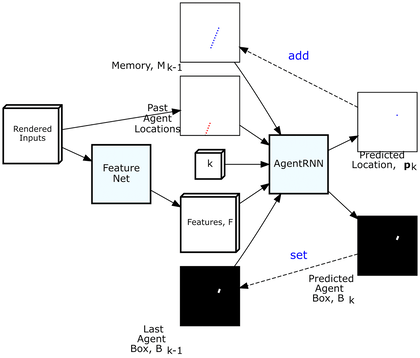
ChauffeurNet has two internal parts, the FeatureNet and the AgentRNN. The AgentRNN consumes an image with a rendering of the past agent poses, a set of features computed by a convolutional network “FeatureNet” from the rendered inputs, an image with the last agent box rendering, and an explicit memory with a rendering of the predicted future agent poses to predict the next agent pose and the next agent box in the top-down view. These predictions are used to update the inputs to the AgentRNN for predicting the next timestep.
Imitating the Good
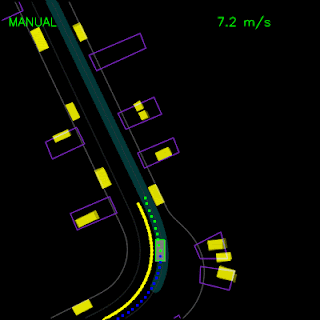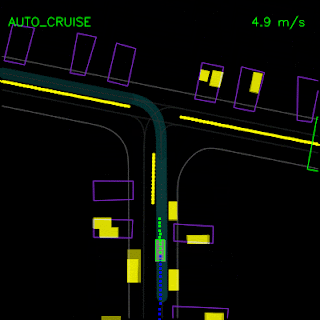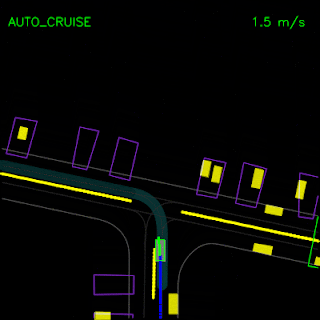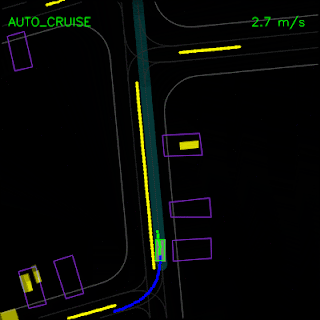
We trained the model with examples from the equivalent of about 60 days of expert driving data, while including training techniques such as past motion dropout to ensure that the network doesn’t simply continue to extrapolate from its past motion and actually responds correctly to the environment. As many have found before us, including the ALVINN project back in the 1980s, purely imitating the expert gives a model that performs smoothly as long as the situation doesn’t deviate too much from what was seen in training. The model learns to respond properly to traffic controls such as stop signs and traffic lights. However, deviations such as introducing perturbations to the trajectory or putting it in near-collision situations cause it to behave poorly, because even when trained with large amounts of data, it may have never seen these exact situations during training.
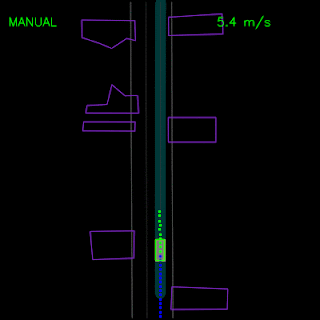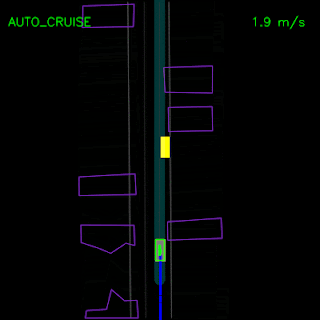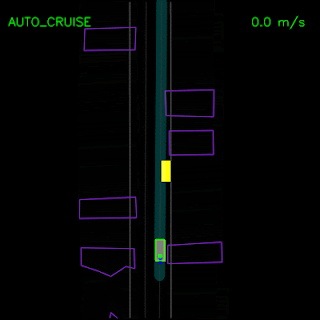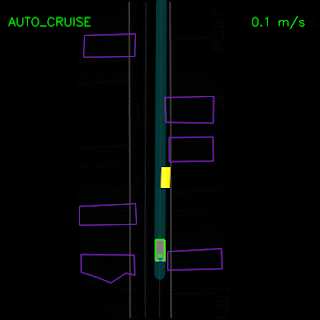
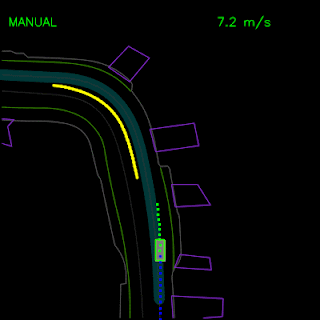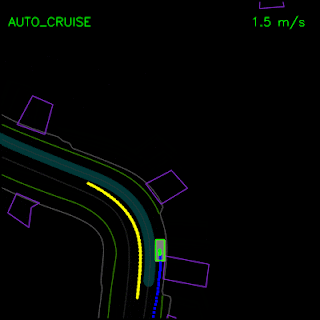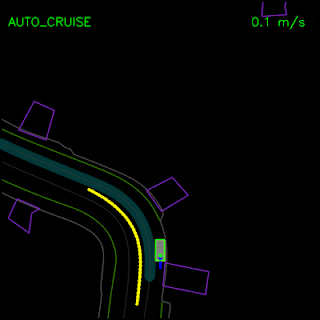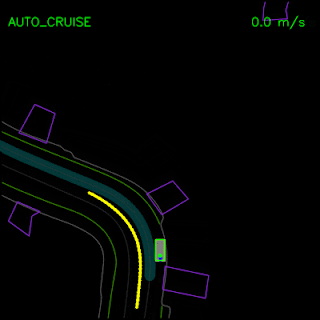
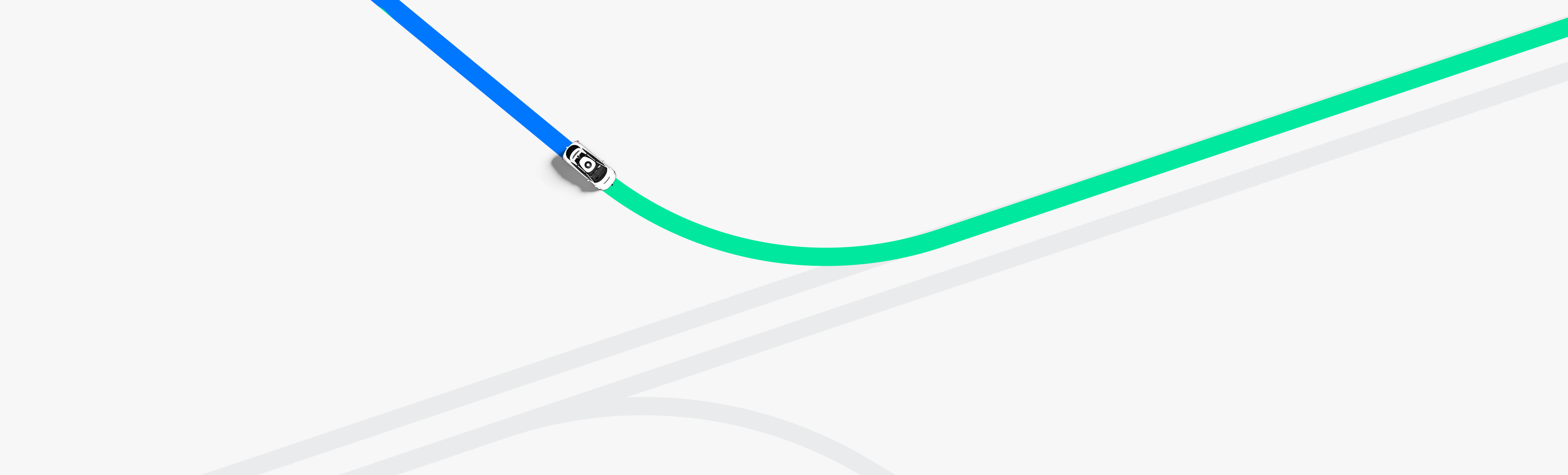
Agent trained with pure imitation learning gets stuck behind a parked vehicle (top) and is unable to recover from a trajectory deviation while driving along a curved road (bottom). The teal path depicts the input route, yellow box is a dynamic object in the scene, green box is the agent, blue dots are the agent’s past positions and green dots are the predicted future positions.
Synthesizing the Bad
Expert driving demonstrations obtained from real-world driving typically contain only examples of driving in good situations, because for obvious reasons, we don’t want our expert drivers to get into near-collisions or climb curbs just to show a neural network how to recover in these cases. To train the network to get out of difficult spots, it then makes sense to simulate or synthesize suitable training data. One simple way to do this is by adding cases where we perturb the driving trajectory from what the expert actually did. The perturbation is such that the start and end points of the trajectory stay the same, with the deviation mostly occurring in the middle. This teaches the neural network how to recover from perturbations. Not only that, these perturbations generate examples of synthetic collisions with other objects or the road curbs, and we teach the network to avoid those by adding explicit losses that discourage such collisions. These losses allow us to leverage domain knowledge to guide the learning towards better generalization in novel situations.
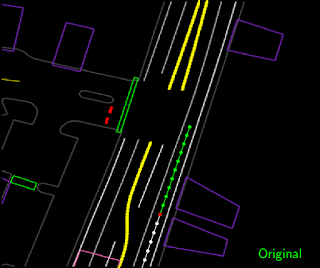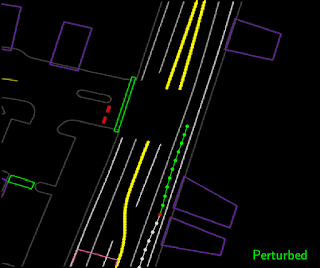
Trajectory perturbation by pulling on the current agent location (red point) away from the lane center and then fitting a new smooth trajectory that brings the agent back to the original target location along the lane center.
This work demonstrates one way of using synthetic data. Beyond our approach, extensive simulations of highly interactive or rare situations may be performed, accompanied by a tuning of the driving policy using reinforcement learning (RL). However, doing RL requires that we accurately model the real-world behavior of other agents in the environment, including other vehicles, pedestrians, and cyclists. For this reason, we focus on a purely supervised learning approach in the present work, keeping in mind that our model can be used to create naturally-behaving “smart-agents” for bootstrapping RL.
Experimental Results
We saw how the pure imitation-learned model failed to nudge around a parked vehicle and got stuck during a trajectory deviation above. With the full set of synthesized examples and the auxiliary losses, our full ChauffeurNet model can now successfully nudge around the parked vehicle (top) and recover from the trajectory deviation to continue smoothly along the curved road (bottom).
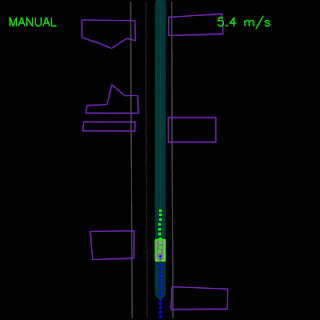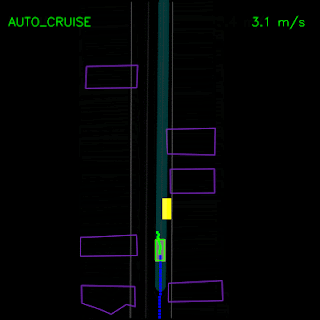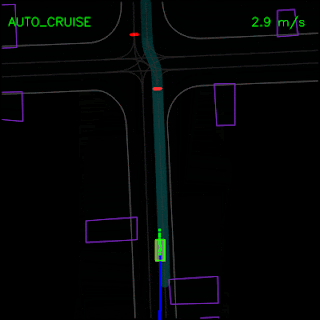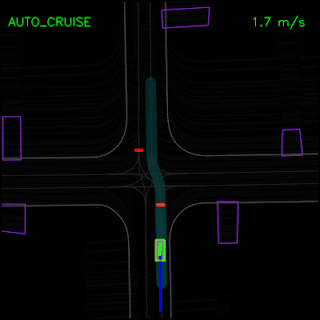
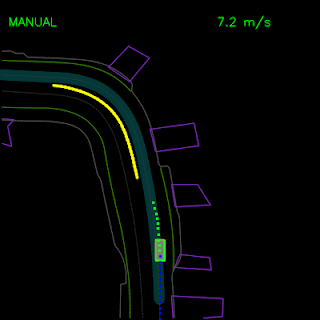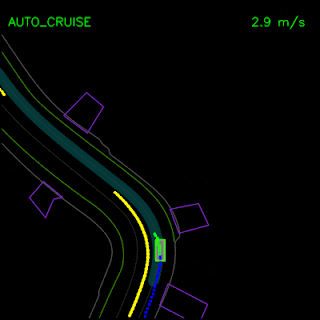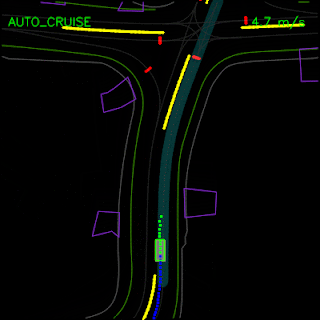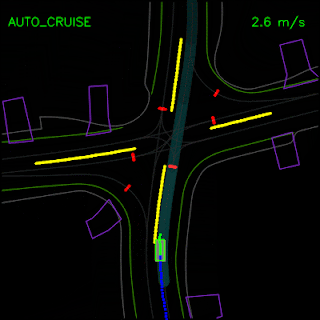
In the examples below, we demonstrate ChauffeurNet’s response to the correct causal factors on logged examples in a closed-loop setting within our simulator. In the top animation, we see the ChauffeurNet agent come to a full stop before a stop-sign (red marker). In the bottom animation, we remove the stop-sign from the rendered road and see that the agent no longer comes to a full stop, verifying that the network is responding to the correct causal factors.
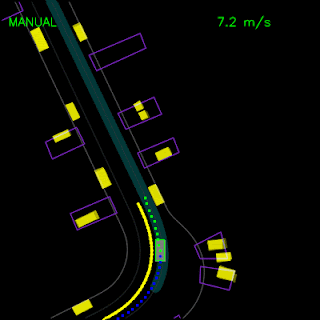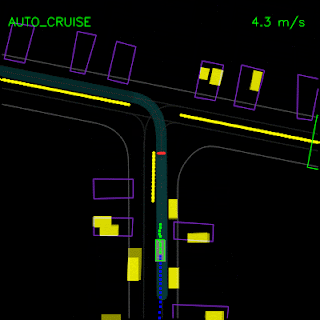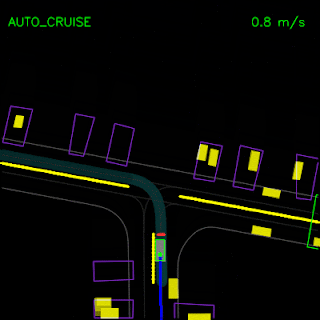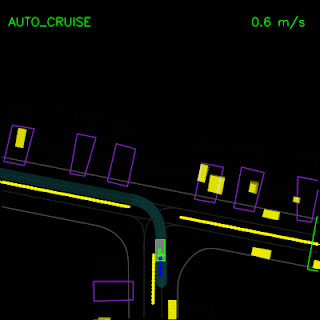
In the top animation below, we see the ChauffeurNet agent stop behind other vehicles (yellow boxes) and then continuing as the other vehicles move along. In the bottom animation, we remove the other vehicles from the rendered input and see that the agent continues along the path naturally since there are no other objects in its path, verifying the network’s response to other vehicles in the scene.
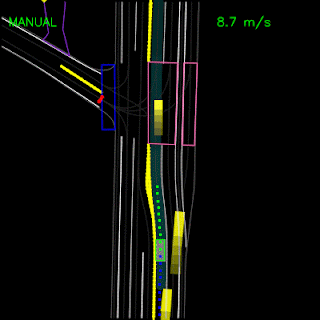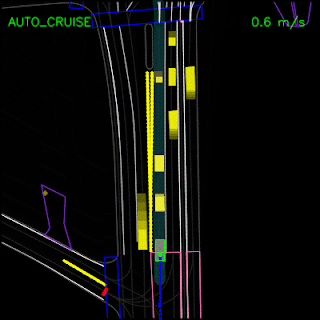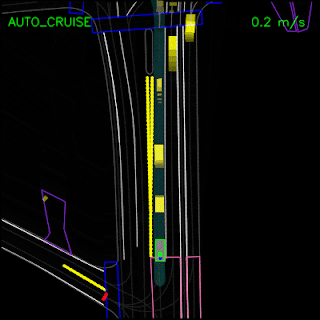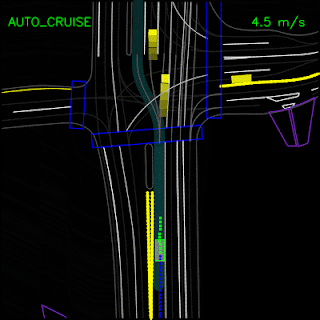
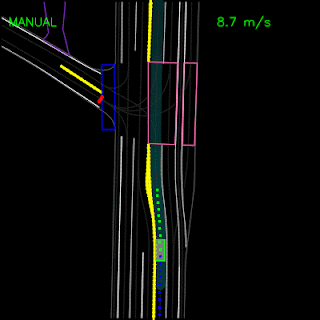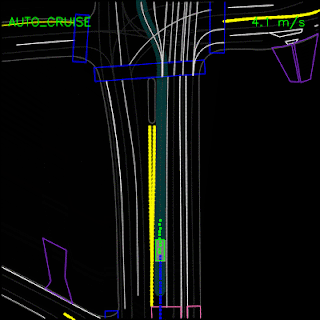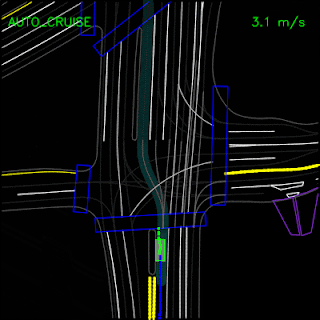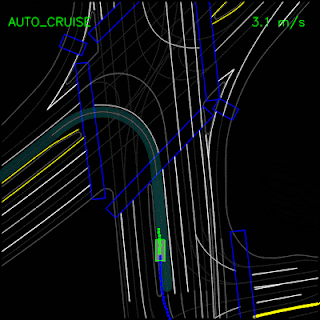
In the example below, the ChauffeurNet agent stops for a traffic light transitioning from yellow to red (note the change in intensity of the traffic light rendering which is shown as the curves along the lane centers) instead of blindly following behind other vehicles.
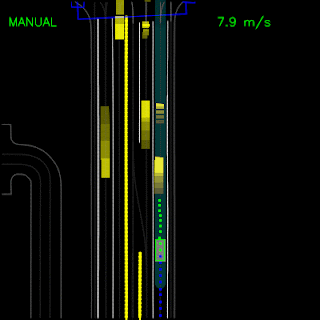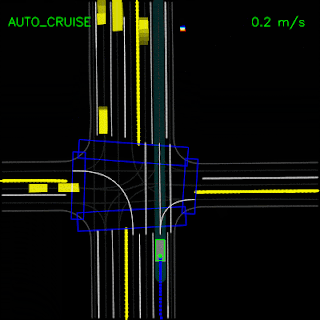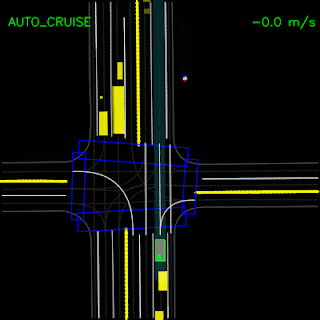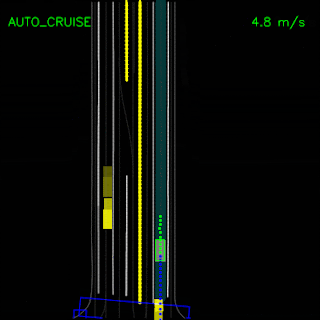
After testing in simulation, we replaced our primary planner module(s) with ChauffeurNet and used it to drive a Chrysler Pacifica minivan on our private test track. These videos demonstrate the vehicle successfully following a curved lane and handling stop-signs and turns.
The example below demonstrates predictions from PerceptionRNN on a logged example. Recall that PerceptionRNN predicts the future motion of other dynamic objects. The red trails indicate the past trajectories of the dynamic objects in the scene; the green trails indicate the predicted trajectories two seconds into the future, for each object.
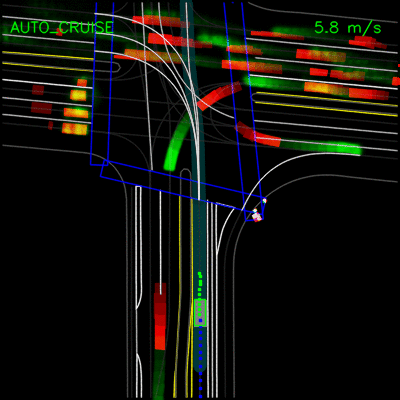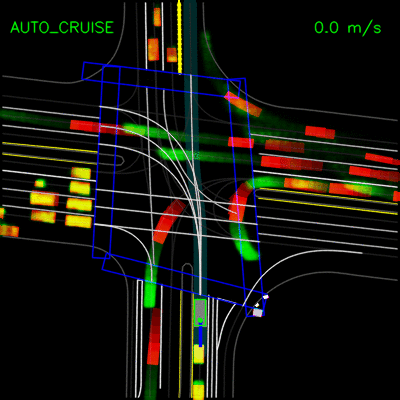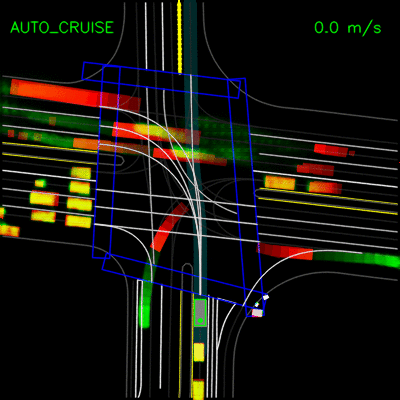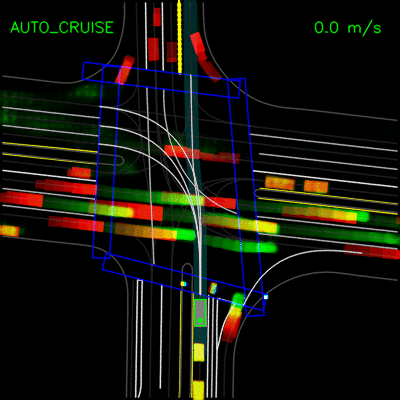
The Long Tail, Causality & Lifelong Learning
Fully autonomous driving systems need to be able to handle the long tail of situations that occur in the real world. While deep learning has enjoyed considerable success in many applications, handling situations with scarce training data remains an open problem. Furthermore, deep learning identifies correlations in the training data, but it arguably cannot build causal models by purely observing correlations, and without having the ability to actively test counterfactuals in simulation. Knowing why an expert driver behaved the way they did and what they were reacting to is critical to building a causal model of driving. For this reason, simply having a large number of expert demonstrations to imitate is not enough. Understanding the why makes it easier to know how to improve such a system, which is particularly important for safety-critical applications. Furthermore, if such improvements can be performed in an incremental and targeted manner, a system can continue learning and improving indefinitely. Such continual lifelong learning is an active field of research in the machine learning community.
The planner that runs on Waymo vehicles today uses a combination of machine learning and explicit reasoning to continuously evaluate a large number of possibilities and make the best driving decisions in a variety of different scenarios, which have been honed over 10 million miles of public road testing and billions of miles in simulation. Therefore, the bar for a completely machine-learned system to replace the Waymo planner is incredibly high, although components from such a system can be used within the Waymo planner, or can be used to create more realistic “smart agents” during simulated testing of the planner.
Handling of long-tail situations, understanding causality, and continual lifelong learning are subjects of active research at Waymo, as well as in the broader machine learning community. We’re always looking for talented researchers to join us as we tackle these challenging problems in machine learning, so get in touch at waymo.com/joinus.
For more details about this work, please see our paper:
* ChauffeurNet: Learning to Drive by Imitating the Best and Synthesizing the Worst Mayank Bansal, Alex Krizhevsky, Abhijit Ogale(Supplementary material)